Test Time Training for Policy Learning
As humans we have this ability to succeed at tasks that take several attempts to get right — inserting keys into holes, throwing objects into a basket, hammering a nail. We modify the way we approach the task based on our failures, using our working memory to remember what we’ve already tried so that we aren’t blindly repeating the same attempt. Robotics Foundation Models (RFM) have only recently acquired memory [1,2], with this new found capability considered SOTA right now. Different methods are being explored to add this capability with one of the simplest approaches to feed past observations back into the model’s context window so that they’re available to attention at inference time. But this scales quadratically with history length, which constrains how much of the past a transformer can actually carry into a decision. Image-based policies make this worse: each frame is many tokens, so context fills fast, and any inference slowdown directly impacts the frequency of the control-loop, impacting the reactivity of the policy.
Test-Time Training (TTT) is a meta-learning objective that takes a different route: instead of attending over history, the model adapts to it, by running self-supervised gradient descent at test time. The original motivation for TTT was domain adaptation, closing the train/test distribution gap for CNN classifiers under covariate shift [3]. More recently, End-to-End Test-Time Training (TTT-E2E) [4] extended this idea to LLMs as a mechanism for adapting on the fly during generation. We are the first to our knowledge to explore extending TTT to Imitation Learning for robotics policies, with the specific goal of adding working memory to policies operating in environments where memory is required.
We investigate, at a small-data scale on toy tasks designed around memory, whether our policy adaptation of TTT-E2E approaches the performance of a full-context transformer while preserving the constant per-step inference cost it promises.
Background
TTT-E2E [4] adapts a model’s weights at deployment time using data that the model has observed. At each step the model takes the recent context, runs SGD on a subset of the network weights to minimise its next-token prediction loss on that context, and only then proceeds to make a prediction for the given task. Simply, weights are updated during inference using next-token prediction as the goal.
For example: imagine a model reading several pages of formal writing and then being asked to continue in the same register. A standard transformer matches the formality by attending back to those pages each time it picks a word, keeping every prior detail accessible. TTT-E2E instead compresses the register into its weights mid-stream, so subsequent generation inherits the tone without needing to attend back. Memory has moved from attention to adaptation.
The network is split into a prefix held fixed at deployment and a suffix whose MLP weights are updated at inference. Embeddings, normalisation and attention stay in the prefix because including them within the adaptation step causes instabilities. For training, the model must learn to adapt to using weights that change over time. To accomplish this, there are two optimisations happening: an inner loop that adapts the suffix, and an outer loop that adapts both the prefix and the suffix. Training is therefore a meta-learning procedure: the outer loop minimises the loss after the inner-loop SGD steps have been applied. The network is explicitly optimised to be adapted rather than just augmented with an adaptation mechanism.
Adapting to robotics
Robot policies are heterogeneous in their inputs (state vectors, prior actions, images) and their outputs are an action distribution. We replace the inner-loop next-token cross-entropy with mean-squared error between the model’s predicted next-observation embedding and the embedding of the actually-observed next state, computed by the same observation encoder; the outer loop optimises action cross-entropy via the policy head, with the same observation MSE included as a small auxiliary term. The inner loop therefore has a dense, label-free supervisory signal: every observation that arrives at deployment time is a fresh training example, and we need no reward, action label, or external feedback.
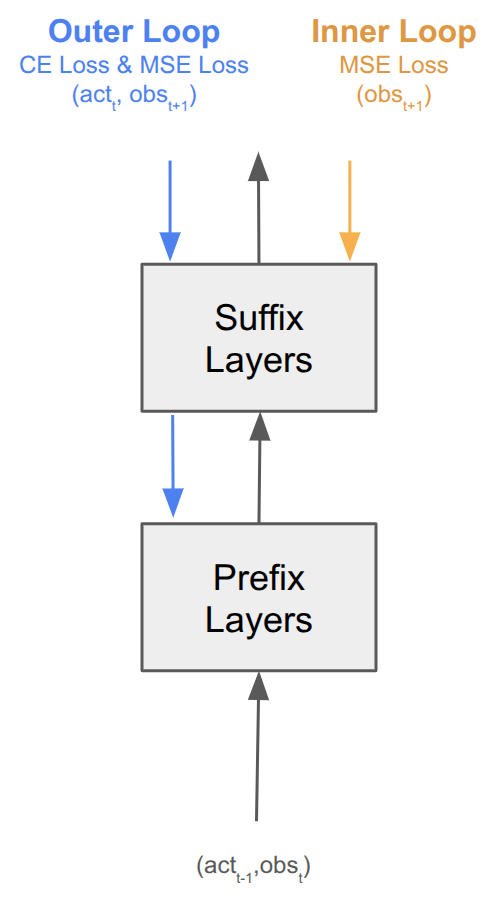
Figure 1: A simplistic view showing an overview of the network for TTT-Policy. The network is split into Prefix and Suffix Layers with the input being the most recent observations and actions. For inner-loop updates an MSE loss on observation embeddings is used to update the suffix layers. For outer-loop updates both CE loss on actions and MSE loss on observation embeddings are used to update both the suffix and prefix layers.
We also tighten the attention mask such that the prefix can only attend to the most recent observation and action tokens. The suffix attends causally within chunks of $M=16$ tokens (8 pairs of observations and actions).
Long-range memory is therefore forced to propagate through the inner-loop weight updates rather than through attention.
We call this combined adaptation TTT-Policy, and use that name throughout the rest of the post.
Baselines
We compare TTT-Policy against two transformer baselines with the same backbone and outer optimizer:
- Full attention, the upper bound. The transformer attends causally over the entire interleaved
(obs, action)history of the episode. - Single-step (ctx=1), the lower bound. The transformer sees only the current observation.
TTT-Policy shares the single-step context of the lower-bound baseline but compensates via inner-loop adaptation. The empirical question is where its performance lands relative to these two bounds.
Environments
We use three environments in our experiments. Each has a heuristic policy that generates the demonstrations our policies are trained on, designed to mimic the kinds of failure modes a person would produce when attempting the task without full state.
All three environments require memory. Two are non-Markovian: at any single instant the full state of the world is not available to the agent, so it has to use the history of past observations to build a complete model of the state. The third is fully observable at every step, but contains a confounding variable that is only discernible by observing a sequence of actions and the resulting states.
Mystery Path
A grid-world from Memory Gym [5]. A narrow walkway (shown in white in Fig. 3) leads from the start cell (blue) to the goal cell (green). The agent has no visibility of the path itself; Fig. 2 shows what the agent actually sees. Stepping off the path resets the agent back to the start cell (but does not reset the episode). The agent has up to 128 steps to reach the goal. To complete the task efficiently, the agent needs to keep track of which states and actions lead off the path, thus eventually finding the path to the goal.

Figure 2: Agent view of the mystery path world

Figure 3: Mystery path privileged state view.
Coin Search
A memory task derived from Memory Gym’s Endless Searing Spotlights. The agent moves in a 2D arena and collects coins that spawn one at a time. The privileged view of the environment can be seen in Fig. 5. Both the agent and the active coin appear for only a single step at the episode start or when the agent has collected a coin and the next coin appears, see Fig. 4. Outside of this, the agent’s position and the coin’s position are no longer directly accessible — the agent has to dead-reckon its own position from its action history and remember where the most recently spotted coin was.
Episodes terminate after 180 steps. The spotlight-damage and visual-occlusion dynamics of the original task are disabled in this variant; the only thing driving behaviour is the visibility-window memory requirement.

Figure 4: Coin Search as seen by the agent where the agent and coin disappear.

Figure 5: Coin Search privileged state view.
Confounded Controls
A goal-reaching task on a 2D plane. The agent picks from eight directional commands (cardinal + diagonal) and sees its own position and the goal’s position. The catch: every episode samples a hidden perturbation of the action frame — a random rotation and an optional left-right flip — so that pressing up might actually push the agent North-North-West. To make things worse, repeating the same action accumulates extra “curl” rotation (with the sign sampled per episode), so naive policies that lock onto one direction spiral away from the goal.
The state is fully observable, but the task is non-Markovian: the action-to-effect mapping can only be inferred from past actions and the movements they produced. Memory is required even though no part of the world is hidden. Episodes terminate when the agent reaches the goal or after 300 steps. Fig. 6 shows a series of episodes by the heuristic policy, with the agent’s path tracing the inferred frame.

Figure 6: Confounded Controls rendering showing the agent, goal and path taken by the agent.
Results
The hypothesis in this restricted domain is that full attention will be the best performer whilst a transformer with a single observation context will perform the worst. We expect TTT-Policy to be upper-bounded by full attention. The state-based results recover the expected ordering across all three environments, but the magnitude of the gap between TTT-Policy and full attention varies with the structure of the memory required.
Table 1. Success rates of the three methods across our three memory environments. All numbers are best-checkpoint success on newly generated episodes.
| Method | Mystery Path | Coin Search | Confounded Controls |
|---|---|---|---|
| Full attention | 95% | 99.5% | 78.5% |
| TTT-Policy (ctx=1 + inner SGD) | 80% | 89% | 38% |
| Single-step (ctx=1, no memory) | 5% | 16% | 0.5% |
On Mystery Path the ordering matches the hypothesis with a narrow gap. The single-step baseline collapses to 5% success, confirming that no Markovian policy suffices and that the task genuinely requires memory. TTT-Policy reaches 80% success while accessing only a single observation in context, within roughly 13 percentage points of the full-attention ceiling. Inner-loop adaptation is performing as memory to enable the agent to accomplish the task.
On Coin Search TTT-Policy most closely approaches the full-attention ceiling of the three environments. Full attention saturates the task at 99.5% success, TTT-Policy reaches 89%, and the single-step baseline reaches 16%. The ctx=1 floor sits above zero because the K=1 visibility window still occasionally lines up with a frame where the coin is overhead, allowing a memoryless policy to pick it up reactively without using any memory. TTT-Policy recovers the rest of the gap by adapting its suffix weights to the most recently observed coin position over the roughly 10 dark frames between glimpses. The gap to full attention is the narrowest of any environment we tested, at about 10 percentage points.
On Confounded Controls the gap is substantially larger. Full attention reaches 78.5% and the single-step baseline is near zero (the model only reaches the goal by chance), while TTT-Policy attains only 38%, a gap of roughly 40 percentage points below full attention.
The contrast across the three environments suggests a structural distinction in the kinds of memory captured by the inner loop. On Mystery Path and Coin Search the relevant memory is discrete and event-anchored: a list of directions to avoid at each waypoint, or the location of the most recently observed coin. Inner-loop weight updates encode this class of “remember this anchor” constraint effectively. On Confounded Controls the relevant memory is a continuous latent, the rotation angle and flip parity of the action frame, that must be repeatedly applied to transform every future action. The inner-loop architecture does not capture this latent as cleanly as the full-attention baseline, which attends over the entire history and can condition each action on the inferred perturbation directly.
Complexity
TTT-Policy inherits a central claim from TTT-E2E: constant per-step inference cost, independent of episode length. Full attention is $O(T^2)$ in compute and memory at the per-step level. TTT-Policy with prefix caching is $O(M)$ per (obs, action) pair, where $M$ is the inner-loop mini-batch size (16 in our configuration), and is therefore independent of $T$.
We measured inference cost empirically on an H100 across episode lengths $T \in [16, 8192]$, using the Mystery Path experimental configuration: $D=512$, $L=4$, $H=2$, $M=16$, ctx=128, where $D$ is the embedding dimension, $L$ the number of transformer layers, $H$ the number of attention heads, $M$ the inner-loop mini-batch size in tokens, and ctx the per-episode token budget the model was trained with.
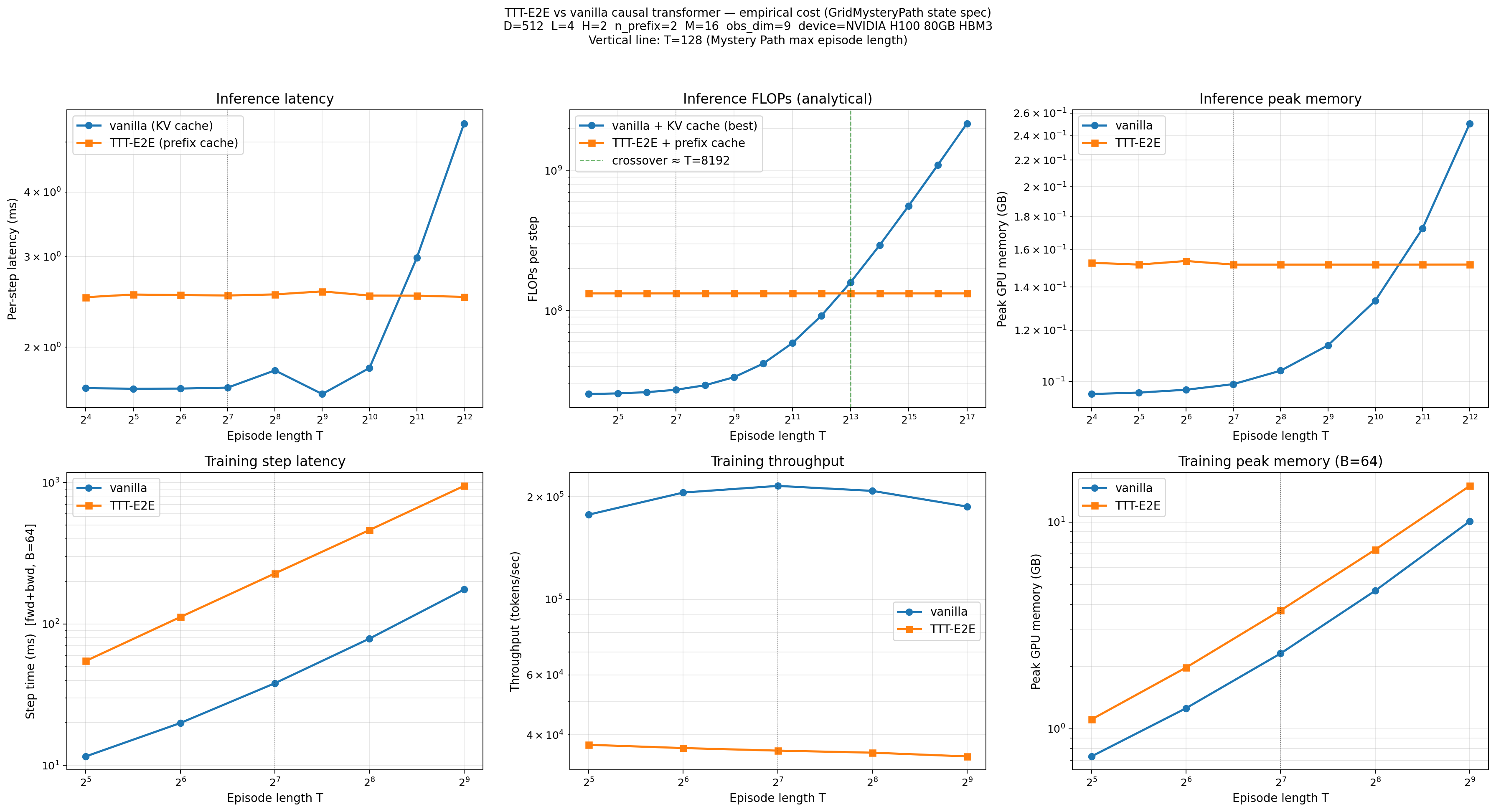
Figure 7. Per-step inference cost and training cost for full attention with KV caching versus TTT-Policy with prefix caching, plotted against per-episode context length T. Measured on an H100 with the Mystery Path environment.
Two cost axes matter: training and inference. TTT-Policy loses on both at the scale of these experiments, but for different reasons.
At inference, TTT-Policy carries a roughly 50 MB constant overhead from cloned suffix parameters and the second-order autograd graph kept for inner SGD, and its per-step latency is dominated by the inner-loop updates rather than by attention. Full attention with a KV cache scales quadratically with episode length but is the lightest and fastest option up to $T \approx 1400$ on our configuration; the analytical FLOPs crossover lies further out at $T \approx 8192$. The episodes in this study cap at 128–300 steps, well below either crossover, so full attention wins on every axis we measure. It is worth noting that inference latency could be further improved for TTT-Policy by doing asynchronous updates at the expense of additional resources.
At training, the gap runs the other way. TTT-Policy trained 2.7× slower than the same-backbone full-attention baseline on Confounded Controls, and roughly 8× slower on the diffusion-policy Mystery Path setup. The cost is the second-order autograd graph maintained through the inner SGD steps, kept for every chunk in the outer loop. Whatever TTT-Policy saves at deployment has to be paid up front, many times over.
When does TTT-Policy become the cheaper deployment choice? Once per-episode context is in the thousands of tokens: long-horizon manipulation rollouts, long-context language-conditioned policies, or any system whose episodes are measured in minutes of robot time rather than seconds. At that scale the constant-time inference promise translates into a real saving, and the extra training cost amortises over many inference steps. For the short-horizon tasks in this post, with episodes capped at 128–300 steps, T is far below that crossover.
Outlook
TTT is an intriguing method for imbuing policies with memory, and at this scale we see that it is effective at allowing an agent to make use of its past states and actions. With single-purpose policies such as these we see early evidence of agents learning from their runtime environment, albeit in a limited way. Looking forward, we are interested in memory as a means of contextual adaptation for RFMs more broadly, TTT being only one such mechanism. Scaling these memory mechanisms to RFM-size models is where it gets interesting. That is the regime where emergent capabilities like in-context adaptation start to become possible.
Two follow-up directions are worth mentioning. We ran preliminary image-based experiments alongside the state-based runs reported above, and saw early signs that TTT-Policy can still capture memory under pixel inputs. We also ablated the inner- and outer-loop loss terms on Mystery Path. The strongest configuration we found uses an MSE-only inner loop (next-observation reconstruction as the sole inner objective), paired with an outer loop that combines action cross-entropy with a small (0.01×) auxiliary state-prediction MSE term. We interpret this result as the inner loop acting as memory that adapts the MLP weights to understand environmental dynamics, while the outer loop is left to focus on selecting the right actions.
To Cite
@misc{collins2026ttt_policy,
author = {Collins, Jack and the {Cobot Foundation Models Team}},
title = {Test Time Training for Policy Learning},
year = {2026},
month = May,
url = {https://blog.jacktcollins.com/2026/05/28/test-time-training-for-policy-learning.html}
}
References
[1] M. Torne, K. Pertsch, H. Walke, K. Vedder, S. Nair, B. Ichter, A. Z. Ren, H. Wang, J. Tang, K. Stachowicz, K. Dhabalia, M. Equi, Q. Vuong, J. T. Springenberg, S. Levine, C. Finn, and D. Driess, “MEM: Multi-Scale Embodied Memory for Vision Language Action Models,” arXiv preprint arXiv:2603.03596, Mar. 2026. Available: https://arxiv.org/abs/2603.03596
[2] D. Kim et al., “RLDX-1 Technical Report,” arXiv preprint arXiv:2605.03269, May 2026. Available: https://arxiv.org/abs/2605.03269
[3] Y. Sun, X. Wang, Z. Liu, J. Miller, A. A. Efros, and M. Hardt, “Test-time training with self-supervision for generalization under distribution shifts,” in Proc. 37th Int. Conf. Machine Learning (ICML), vol. 119, Jul. 2020, pp. 9229–9248.
[4] A. Tandon, K. Dalal, X. Li, D. Koceja, M. Rød, S. Buchanan, X. Wang, J. Leskovec, S. Koyejo, T. Hashimoto, C. Guestrin, J. McCaleb, Y. Choi, and Y. Sun, “End-to-End Test-Time Training for Long Context,” arXiv preprint arXiv:2512.23675, Dec. 2025. Available: https://arxiv.org/abs/2512.23675
[5] M. Pleines, M. Pallasch, F. Zimmer, and M. Preuss, “Memory gym: Towards endless tasks to benchmark memory capabilities of agents,” in Proc. Int. Conf. Learning Representations (ICLR), May 2023.